

Qualitative Research လုပ်ငန်းတွေမှာ ခေတ်ပေါ် AI စနစ်တွေကို ထည့်သွင်းအသုံးပြုခြင်း
Qualitative Data ကို သမားရိုးကျနည်းလမ်းနဲ့ လုပ်ရင် အချိန်ကုန်တယ်၊ ငွေကုန်တယ်။ အရင် လုပ်ဖူးတဲ့ အတွေ့အကြုံအရ (လက်ကိုင်ဖုန်း လူတိုင်း မသုံးနိုင်တဲ့ ခေတ်မှာ) Interview လုပ်မယ့် လူတွေ သုံးဖို့ Voice Recorder ဝယ်ပေးရတယ်။ Recorder ခလုပ်တွေကို သုံးတတ်အောင်၊ ယဉ်ပါးအောင် လေ့ကျင့်ပေးရတယ်။ ဖုန်းတွေ ပေါ်လာတော့ Recorder ဝယ်ခြမ်းရေး၊ ပြင်ဆင်ရေး အတွက် ငွေ မကုန်တော့ဘူး။
Field Data Collection လုပ်သူတွေက သူတို့ လက်ကိုင်ဖုန်းနဲ့ အသံဖမ်းတယ်။ အသံဖိုင်ကို ပြန်အပ်တယ်။ Data Processing လုပ်ဖို့ အဆင့်မှာ အသံဖိုင်တွေကို တစ်ယောက်ချင်းဆီက ကူးယူရတယ်။ File Name တွေ မမှားအောင်၊ Backup တွေ သေချာအောင် လုပ်ရတယ်။ Sensitive ဖြစ်တဲ့ Data တွေ ပါရင် အဲဒီ File တွေကို Encryption လုပ်ရမယ်။ Access Code တွေ ပြန်ခွဲရမယ်။ အချိန်တွေ ကြာတယ်။
အသံဖိုင်တွေကို စာသား (Transcript) အဖြစ် ပြောင်းဖို့ လူ အင်အား သုံးရတယ်။ ၏ သည် ၍ မလွဲအောင် Transcript ရေးခိုင်းဖို့ ဆိုရင် စျေးက ပိုများတယ်။ Sensitive ဖြစ်တဲ့ Data တွေ ပါရင် Transcript လုပ်မယ့်သူ သုံးဖို့ ကွန်ပြူတာ ထုတ်ပေးရဦးမယ်။ လူ အင်အား သုံးပြီး Transcription လုပ်ရင် (ကိုယ့် အတွေ့အကြုံအရ) အချိန်ကြာတယ်၊ ငွေကုန်တယ်၊ အမှားအယွင်း မကင်းဘူး။
ရလာတဲ့ Transcript ကို ပြန်ပြီး Content Analysis လုပ်ရင်လည်း လူအင်အား တော်တော် သုံးရတယ်။ QDA App တွေကို သုံးတတ်တဲ့သူ ငှားရဦးမယ်။ QDA App နဲ့ Analysis လုပ်ဖို့ Codebook ရေးရဦးမယ်။ QDA App နဲ့ Coding လုပ်သူက ပေါ့တန်တန် လုပ်ရင် Quality ကျသေးတယ်။ ဒီတော့ကာ Quality Control ပြန်လုပ်ဖို့ လူထပ်ငှားရဦးမယ်။
LLM တွေ အလျှိုလျှို ပေါ်လာတဲ့ အခါမှာ ဒီကိစ္စတွေကို လွယ်လင့်တကူ ရှင်းလို့ ရသွားတယ်။ ကုန်ကျစရိတ်ကိုလည်း လျှော့ချလို့ ရသွားတယ်။
ကိုယ့် လုပ်ငန်းခွင်ထဲက လုပ်ဖော်ကိုင်ဖက် သုတေသီတွေ Qualitative Data Collection & Analysis လုပ်ရင် လွယ်အောင် ဟိုစပ်စပ် ဒီစပ်စပ် ဖြတ်ညှပ်ကပ်တွေ စမ်းကြည့်ဖြစ်တယ်။ ကိုယ် လိုအပ်တာနဲ့ ကွက်တိကျတဲ့ One Stop Solution တော့ မတွေ့သေးဘူး။ Python Libraries တွေ ရေးထားတဲ့ ညဏ်ကြီးရှင်တွေ၊ LLM တွေ၊ Cloud Computing လုပ်တဲ့ လုပ်ငန်းတွေကြောင့် အလုပ် ပိုတွင်တယ်။
Workflow က သိပ် မခက်ဘူး။ Qualitative Interview တွေ လုပ်တဲ့ အခါမှာတော့ Field Data Collection လုပ်သူတွေ အနေနဲ့ App သုံးပြီးတော့ Conversation/Interview ကို Recording လုပ်မယ်။ Recording File ကို MP3 Format နဲ့ သိမ်းပြီးတော့ တခြားသူတွေ Download လုပ်လို့ ရမယ့် နေရာ တစ်နေရာရာ Cloud-based Storage ထဲ ထည့်လိုက်မယ်။
MP3 Audio File တွေကို Python Library တစ်ခုခု သုံးပြီး Text to Speech လုပ်မယ်။ Text File အနေနဲ့ သိမ်းတယ်။ အဲဒီ Text File တွေကို LLM သုံးပြီးတော့ Content Analysis လုပ်ခိုင်းမယ်။ Word Frequency Counting တွေ လုပ်ခိုင်းမယ်။ Similar/Different Themes/Topics တွေ ပြန်ထုတ်ခိုင်းမယ်။ Summary လုပ်ခိုင်းမယ်။ Figures Numbers တွေ ပါရင် ဆွဲထုတ်ခိုင်းမယ်။ နေရာဒေသ နာမည်တွေ ပါရင် WKB Geometric Data သုံးပြီးတော့ Geo-data ပြန်ထုတ်ယူမယ်။ ပြီးမှ Analyst က Machine-generated Output ကို လူသားညဏ်ရည်နဲ့ ပြန်စစ်မယ်။ စက် နားမလည်နိုင်တဲ့ နောက်ခံ အခြေအနေတွေကို လူနဲ့ပဲ ဆင်ခြင် သုံးသပ်လို့ ရမယ်။ ဒီလို စဉ်းစားမိတယ်။ သမားရိုးကျ နည်းလမ်းကို Tools တွေ သုံးပြီး ပိုမြန်အောင် လုပ်တဲ့ သဘောသွားပါပဲ။
Speech to Text ကို ဒီညနေ ကလိကြည့်တော့ (SpeechRecognition 3.11.0 – https://pypi.org/project/SpeechRecognition/) ကို တွေ့တယ်။ သိပ် အဆင် မပြေ။ တခြား Services တွေ ရှာကြည့်တော့ Microsoft Azure Speech (တစ်လကို ငါးနာရီ အခမဲ့ သုံးခွင့် ရှိ) ၊ IBM Watson (တစ်လကို မိနစ် ငါးရာ အခမဲ့ သုံးခွင့် ရှိ) ၊ Google Text to Speech (တစ်လကို တစ်နာရီပဲ အခမဲ့ သုံးခွင့် ရ) သုံးရင် ကောင်းတယ် ဆိုတာ တွေ့တယ်။
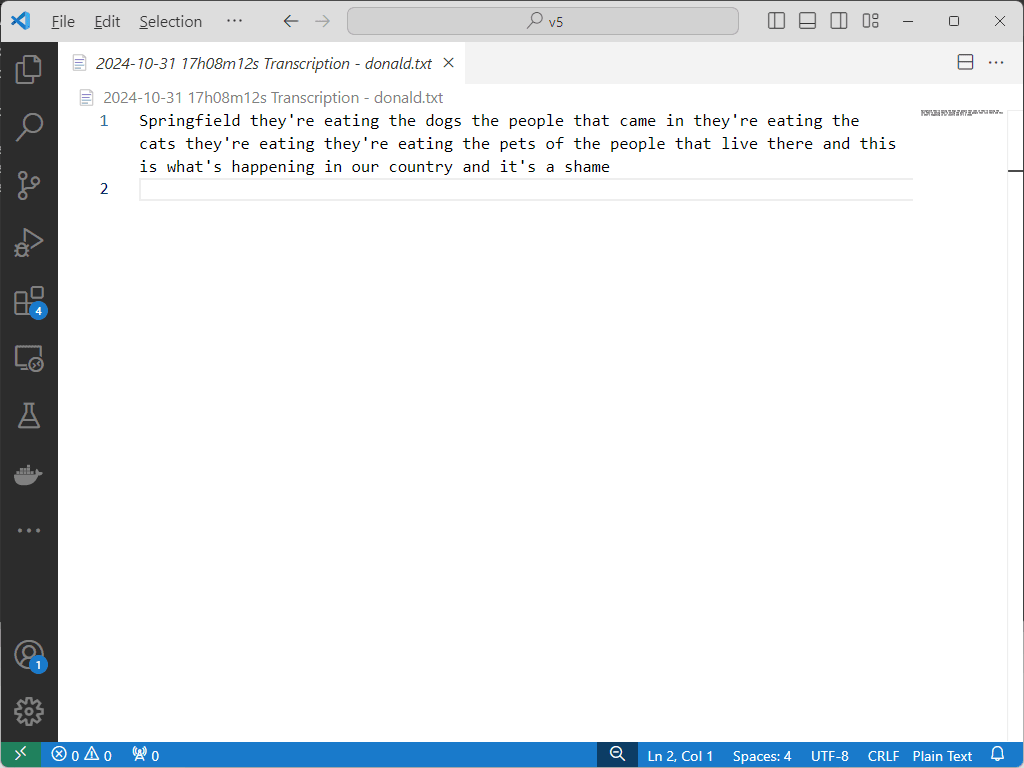
Microsoft Azure က သုံးနေကြ မဟုတ်တော့ API Set-up လုပ်တာ လည်ထွက်နေတာနဲ့ နောက်ဆုံးမှာ Google ရဲ့ Cloud Speech-to-Text API နဲ့ပဲ စမ်းကြည့်လိုက်တယ်။ အဆင်ပြေသွားတယ်။ Donal Trump ရဲ့ “In Springfield they’re eating the dogs” အသံဖိုင်ကို စမ်းကြည့်တာ ထုတ်ပေးတဲ့ စာသားတွေ အကုန် မှန်တယ်။ ကျန်တဲ့ အဆင့်တွေ ဆက်လုပ်ဖို့ပဲ လိုတော့တယ်။
လိုတိုရှင်း ပြောရရင် LLM တွေ ပေါ်လာတာ အပြောင်းအလဲ အကြီးကြီး ဖြစ်သွားပြီ။ မြန်မာနိုင်ငံလို့ Developing Country ကို ဒီ အပြောင်းအလဲ ရောက်ဖို့က အချိန် နည်းနည်း ကြာဦးမယ်။ Western Country တွေမှာ သွားနေတဲ့ အရှိန်ကို မီမှာတော့ မဟုတ်။ ဒါပေမယ့် တစ်ချိန် မဟုတ် တစ်ချိန်တော့ ရောက်လာမှာပဲ။ အဲဒီ အချိန်ကျရင် သုံးရမယ့် Tools တွေက ပိုပြီး အဆင်ပြေသွားမယ်။ လွယ်သွားမယ်။
ပြည်တွင်းမှာ Qualitative Research လုပ်နေသူ မိတ်ဆွေတွေ အနေနဲ့လည်း ခေတ်ပြိုင် Tools တွေ၊ နည်းလမ်းသစ်တွေကို Up-to-date ဖြစ်အောင် ပြင်ရင် မမှားလောက်ဘူး။





